Data Streams & Light Squid Indexers: SQD’s New Game Plan

16 July 2024 - Zug, Switzerland
"Every new beginning comes from some other beginning's end." - Seneca
We began to build SQD in 2021–which could be considered a lifetime ago by crypto startup standards. Following mainnet launch, however, the energy at Subsquid Labs is entirely different than what might be expected. We feel that we are at an entirely new beginning. The protocol is live, but the path toward true decentralization and developer utility has only just begun. This article is intended to publicize just some of our internal thoughts and give shape to our vision for SQD Network over the next year. Decentralization is, by definition, a community effort, and we hope the reader feels moved to become a part, whether it be by contributing code or through other talents, skills, or abilities.
Background
The Hyper-Scalable and Modular Decentralized Data Platform–SQD Network is a decentralized data lake that unlocks granular, permissionless data access at a petabyte scale. The network in its current form is a cluster of worker nodes that stores and serves data to blockchain indexers (in particular ‘Squids,’ but also Subgraphs and other ETLs) in a peer-to-peer manner.
In broad strokes, we have pursued and continue to pursue a vision for the network that aims:
- To provide permissionless access to all sorts of data (both on-chain and off-chain).
- To create a token-gated query interface (‘query engine’) to extract only the data relevant to the developer or other data consumer from the network.
- To enable extremely inexpensive, trustless, and auditable queries with opt-in TEE, ZK, and self-certification.
- To achieve virtually infinite horizontal scalability for the indexing of historical on-chain and off-chain data.
- To build out a token-based curation mechanism for node operators and the datasets that are served to the network.
Much of this vision was outlined in the latest version of the SQD Network Whitepaper, published on August 28, 2023. We encourage everyone to familiarize themselves with that document, and in particular to learn the roles and responsibilities of each network participant, including Worker Node Operators (who make up the data lake cluster), Delegators (who curate the nodes), Data Providers (who submit datasets to the network), and Data Consumers (who run gateways to the network or access ones operated by third parties).
Why SQD Matters
At Subsquid Labs, we believe that the key to unlocking Web3’s next significant boost in adoption lies in enabling fast, cost-efficient, and decentralized access to the ever-growing universe of unstructured data. This is just like how Google accelerated Web2 adoption by accumulating the data available on the World Wide Web and making it easily queryable through a search engine, and how Snowflake and Databricks did the same for analysts and developers.
Of course, there are several fundamental differences between our pursuit and that of Google:
- Owing to how the data is used, the value-per-byte of data in Web3 is orders of magnitude higher than in previous iterations of the web.
- In Web3, the data needs to be consumed by many additional entities and technologies, including AI agents, smart contracts, dApp indexers, and analytics APIs.
- Unlike the Web2 giant that depends on the monetization of data, we aim to create a credibly-neutral access protocol with a lean and simple low-level interface to consume the data. This is key to programmatic adoption, as was the case with HTTP in the early days of the web.
- In Web3, the value of data increases, and the network effect is cemented when it is not fragmented.
- A 100x improvement on decentralized indexing (as pioneered by the Graph) is a perfect launchpad niche for us to bootstrap the adoption flywheel.
While it is hard to predict how the dApp landscape stands to change and develop over the next three to five years, it is clear that a credibly-neutral solution to providing and consuming Web3 data will become a self-enforceable MOAT for SQD. Indeed, we anticipate that SQD Network will be able to serve billions of queries daily, capturing significant market share, including for:
- dApp indexers (our primary focus up till now)
- Smart contract and oracle data access (primary for DeFi use cases)
- Analytics
- Next-gen use cases including AI agents and TEE coprocessors.
In SQD Network’s current form, operation costs per query are already very low ($<0.001). Taking advantage of this fact, we are now entering into a bootstrap phase that only token-gates access to the network without taking fees, enabling organic scaling alongside free data access. After this initial bootstrap phase, a small SQD tax for gateways will be introduced directly into the protocol. The SQD revenue model is and will be discussed elsewhere. Interested readers can check the manner of calculation as outlined in the SQD Network whitepaper.
Past achievements
We have previously told our founding story in some depth on our blog. In short, SQD has gradually gained industry adoption as an indexer since its launch in 2021. Taking a modular approach to data access, Squid-based indexing became the industry’s most flexible and performant data-retrieval solution in the years that followed. In 2023, Subsquid Labs ran the largest data infrastructure testnet ever, wherein over 60,000 decentralized indexers were deployed by at least 17,000 verified developers over the course of multiple testing phases. In January of 2024, SQD held the fastest CoinList sale ever (and the first major token sale of the year), selling out 5% of the token supply in just 19 minutes.
Decentralized Data Lake
On June 3rd, 2024, Subsquid Labs announced the launch of the SQD Network mainnet. At this initial launch, SQD Network is a decentralized data lake composed of data providers, worker node operators, delegators, and data consumers (gateway operators).
Data providers, acting as oracles for ‘big data,’ upload raw blockchain data, which is then compressed and distributed among worker nodes. During the initial bootstrapping, the unique data provider is Subsquid Labs, however this (including data validation) will be decentralized according to the plan presented in this article.
Worker node operators bond a security deposit (100,000 SQD), which can be slashed for byzantine behavior. When requested, the worker node queries its local data using DuckDB. Any query can be verified by submitting a signed response to an on-chain smart contract.
Delegators are generally regular SQD token holders who indicate trustworthy nodes in the network through delegations. Nodes that receive the most delegations have a higher chance of receiving work to do and, as a result, higher rewards. There is currently no minimum delegation requirement in the network and no locking period, meaning curation acts as a real-time, permissionless system of node curation. Delegator rewards are calculated based on the rewards paid out to the relevant worker nodes.
To query the network, data consumers have to operate a gateway or use an external service. Subsquid Labs’ ‘SQD Cloud’ product currently runs a gateway, and several infrastructure providers are in the pipeline to run these as well.Each gateway is bound to an on-chain address.
The number of requests a gateway can submit to the network is capped based on the amount of locked tokens. Consequently, the more tokens locked by the gateway operator, the more bandwidth it is allowed to consume.
One can think of this mechanism as if the locked SQD yields virtual "compute units" (CU) based on the period during which the tokens are locked. Much more information about this model will be made available soon, along with the release of Gateways 2.0, as outlined later in this article.
Since the launch of the mainnet just over one month ago, we have observed significant traction for several of the network roles. At the time of this article’s publication, 811 worker nodes are online, storing 594 TB of onchain data and earning an average APR of 22%. Approximately 71.2 million tokens have been delegated, earning delegators an average APR of 8.1%.
At this early stage, the vast majority of production SQD use cases have yet to be migrated to the decentralized network. Nevertheless, the decentralized data lake has already served 433 TB of data to data consumers.
SQD Indexing
Long before the launch of the decentralized network and the token, SQD built its reputation by providing the industry’s most performant and flexible indexing service. Squid SDK is a TypeScript-based toolkit for high-performance batch indexing, sourcing the data from SQD Network, and previously from the centralized iteration of the data lake. SQD Cloud is a hosted service for custom indexers and GraphQL APIs, that also sources data from the data lake.
Additional plugins include SQD Firehose, a lightweight adapter for running subgraphs against SQD Network, without accessing an archival RPC node, and the ApeWorx SQD plugin, which uses SQD Network as a fast data source for that framework. Moreover, Python developers can access data from the data lake using DipDup SDK (built externally by the Baking Bad team).
As an indexing service, SQD has set itself apart for its speed, reliability, and developer-flexibility. A typical SQD indexer, for example, can process historical blockchain data at tens of thousands of blocks per second–tens and hundreds of times faster than competing tools. SQD uptime is unprecedented for Web3 infrastructure, as can be seen on the official uptime monitor.
Squid SDK is modular, extensible, and compatible with dozens of popular tools and data targets, including Google BigQuery–this feature was recently announced as a part of Subsquid Labs’ official collaboration with Google Cloud.
In terms of traction, SQD has achieved approximately 20% market share, second only to the major incumbent. Using SQD, developers can already index over 150 chains, including any EVM, SVM (Solana), or Substrate (Polkadot) network, as well as Fuel, Tron, and Starknet.
At least 300 dApps depend on Squid SDK each and every day, and well over 5,000 indexers are currently in production. These numbers are conservative, and we at Subsquid Labs expect them to increase drastically as decentralized gateways go live. Gateways will enable us to see how SQD Network data is being used onchain.
A New Game Plan: Why and How
Anybody who reads our earliest whitepaper and our most recent will see that very little has changed in our overarching mission: to re-architect the way decentralized data is handled in order to unlock the peer-to-peer internet for everybody. However, in the over three years since our founding, there have been significant updates in the space, and new technologies made available. For these reasons, we consider it a good time to refactor our tactical game plan.
Keep in mind that SQD Network is a decentralizing protocol with the ambition to become fully decentralized. This means that aspects of the plan may change according to the feedback of the community, and indeed we very much encourage any interested person to provide their input on any part of the vision, just as we welcome open-source contributions to the technology.
Technological Progress and a Changing Landscape
When we first set out to build SQD, Web3 was very much a different place–data at that time was provided to dApp front-ends by simple indexers, and to smart contracts by somewhat primitive oracles. Solutions to expand access to blockspace were quite different too, as higher-layer rollups and appchains were still largely theoretical.
Back then, there was no expectation nor need to provide truly real-time access to data at any kind of significant scale. It wasn’t so important to be able to query across multiple networks, as these chains simply didn’t exist or have any usage. Simple smart contracts on EVM were completely dominant.
Since then, the landscape has completely changed. More data than ever is being posted on-chain. Contributors to this trend include restaking layers like Eigenlayer and Symbiotic, high-throughput L1s like Solana, appchain ecosystem like Cosmos and Polkadot, and the ever-growing availability of data availability solutions as provided by decentralized projects like Celestia and Avail, and by centralized RaaS providers like Caldera and Gelato.
Of course, the more networks are live and the more data t is onchain, the greater the challenges in terms of accessing it. The large incumbents have mostly failed, allowing SQD to gain market share as a result. Developers of applications across use cases have become more ambitious, with ambition going beyond the infrastructure presently available. For today’s DeFi and social use cases, scalability in terms of historical data access as well as real-time data streams has never been more relevant.
Indeed, the old indexer/oracle dichotomy is becoming less and less pertinent. Now, developers want to stream on-chain data to smart contracts, as is certainly necessary for many use cases including AI agents. Particularly in onchain social media use cases, developers need to aggregate both on- and off-chain datasets to be displayed by front-ends.
Data validity is prescient, and fortunately ZK, TEE, and co-processor technology is coming to its own, thanks to providers like Polyhedra, Brevis, Super Protocol, and Phala, to trustlessly provide these proofs.
The new SQD developmental plan, as presented below, takes all these innovations and market demands into account.
A Note on Timeframes and Dates
"The only thing that is constant is change." — Heraclitus
The time estimations and dates shared in this document should not be construed as a contractual obligation or any other kind of ‘promise’ from Subsquid Labs. While it is true that today, and likely for some significant amount of time going into the future, the direction of SQD Network is and will be largely driven by Subsquid Labs, the tenants of decentralization may lead to developmental delays or ‘changes in schedule.’
This could present itself in many ways, via governance or through community activism. New opportunities may arise in the ever-changing world of Web3, and network participants may decide to redirect protocol development in that direction. We embrace this spirit of innovation wholeheartedly and look forward to seeing how the protocol develops in unexpected ways as time passes and adoption grows.
Another consequence of decentralization is that development is unlikely to always be linear: just because an SQD product feature becomes implemented and accessible to network users does not mean that it is yet fully decentralized.
Subsquid Labs follows a product-first protocol development strategy, meaning we always develop features for the network first as testable MVPs before making them production-ready and decentralizing them. In other words, we make sure that real users need and want a feature and bring them onboard to help improve the feature before we move on to decentralizing it.
An example of this is the ‘ArrowSquid’ release of SQD Network blockchain datasets, which was released back in early 2023 and which architecturally are identical to data sets (also called ‘archives’) in today’s mainnet. First, we built the release; then we tested it with a few users; then we onboarded the rest of the users, and only then did we decentralize them fully with two testnets and our recent mainnet launch.
To sum up, while features in this network may go live on a specific date, it is still likely to take some time to coordinate their decentralization across the very rapidly growing network.
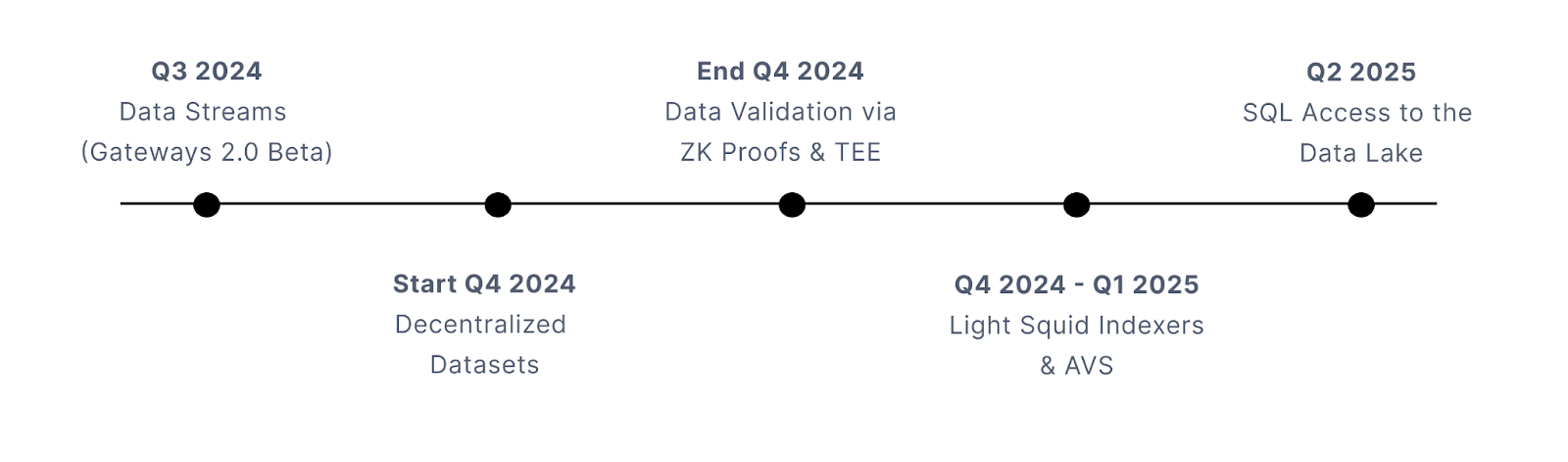
SQD Network’s 2024 Development Game Plan
Throughout the rest of 2024 and until 2026, the primary focus of SQD’s technical development will be on data streams (hot blocks/real-time data), trustless data validations, implementations of ZK proofs and TEE co-processors, SQL queries, permissionless dataset provision, and full indexing decentralization via light squid indexers and AVS deployments.
By the end of this plan, data consumers in SQD Network will be able to retrieve data from the network using decentralized indexers, TEEs, and SQL. It will be possible (as it is today) to send this data on to dApp front- and back-ends, and it will become possible to stream it to smart contracts. The provision of data will be decentralized, and users will be able to submit datasets to the network to make them available for permissionless queries by anybody, anywhere.
Data Streams (Gateways 2.0)
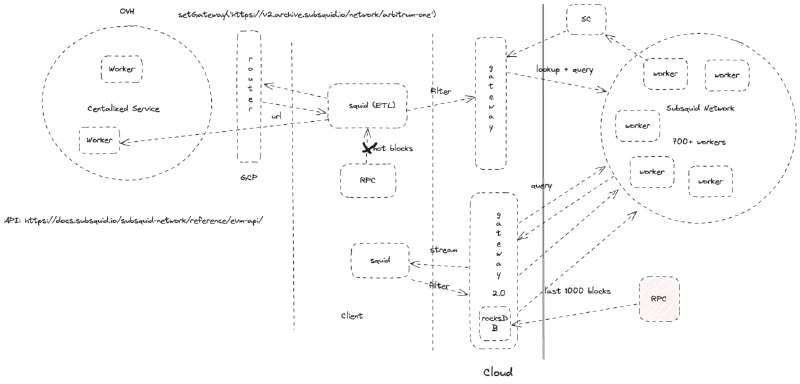
The status quo - To query SQD Network, data consumers have to operate a gateway or use one operated by an external third-party. Presently, SQD gateways are architected in such a way that they can only serve finalized blockchain data at a delay of a few dozen to a few hundred blocks, depending on the particular blockchain’s finality time and how prone that blockchain is to re-orgs. As a result, to get real-time data, data consumers today must depend on an RPC to read/access the latest blocks, including non-finalized (‘hot’) ones.
The goal - With the launch of Gateways 2.0, we will remove data consumers’ dependence on the RPC endpoint, allowing for much more predictable real-time data streams. Thanks to certain architectural changes, Gateways 2.0 will also make squid indexers run against the network with far reduced latency against the network.
Value unlocked - In addition to the increased performance and more trustless access to real-time data for data consumers, the native implementation of data streams to SQD network represents the first step towards unlocking a wide range of additional use cases, including the ability to send data directly to smart contracts (Oracle use case), as will be outlined in more detail below.
The implementation - Gateways will be rearchitected to include hot storage and to handle computations that will no longer need to be handled by the squid (indexer) or client side.
Time estimate - A minimum viable implementation of Gateways 2.0 is on track to begin testing in mid-August. The first gateways will serve Solana data, with EVM, Substrate, and other VMs to be released in quick succession after adequate testing.
Query Verification & Validation
The status quo - The standard for data validity in Web3 today is far too low. Developers and end-users are far too willing to trust data providers. People trust oracles, typically centralized RPC providers, indexers like the Graph, and their centralized alternatives.We believe this is wrong, and are in good company with projects like Space and Time, Kyve, and a range of ZK-protocols that aim to develop solutions to this problem.
The goal - Trustlessness for data access through ZK validity proofs and greater trust at a lower cost for many downstream use cases through TEE implementations.
Value unlocked - SQD’s implementation of data validation technologies will unlock trustlessness for data access from the network, enabling greater decentralization power for use cases that are down the pipeline, like indexers, oracles, and AI agents.
The Implementation - Historically, we at Subsquid Labs have tried our best to ensure the data that is included in the data lake parquet files is sound. However, there is no way to control how worker nodes respond to data consumer requests. This opens up significant problems in terms of data validity, which is a blocker to many trust-minimalized indexing use cases, and certainly not to be allowed when sending data onto a smart contract. Already, we have begun implementing and testing different methods of data validation, taking into account each method’s unique trade-offs.
Ultimately, we intend to offer developers multiple options, which they may choose based on cost considerations and the degree to which trustlessness is required for their use case.
ZK proofs, for instance, are expensive and slow but fully trustless. This may be preferable for sending data to smart contracts. TEEs, on the other hand, are far cheaper but also less secure, and may be chosen for use cases that don’t require such a high level of trustlessness. We expect that some developers may even choose to validate data on centralized servers, which are even lower cost than TEEs but far less secure. This may be adequate for some front-end use cases.
Time estimate - The first ZK and TEE implementations ready for beta testing will be made available in Q4 2024.
SQL Queries
Status quo - Currently, SQD Network filters and stores raw data on a minimal level and validates it. On top of this, developers build squid indexers/ETLs in order to develop richer datasets for quick queries by the apps. For ad-hoc queries, this is not the best solution.
The goal - Much of the data people are interested in can be reduced to a SQL query when available from a specifically designed dataset. These datasets and this query functionality will become available directly from SQD network. In other words, in a permissionless manner, users will be able to ask questions (and get answers relatively quickly) to questions (written in SQL) like:- “What was the average trading volume of SQL/ETH across DEXs on 10/09/2025?”- “What is the current TVL of PancakeSwap exchange on Arbitrum and BNB Chain?” - “Tell me my token holdings across all EVM chains”
Value unlocked - The primary value-add from the introduction of SQL to SQD Network is decentralization and the second-order effects of decentralization (reduced infra cost), enabling users to receive rapid responses to questions relating to Web3 in a P2P manner.
On top of this, one could build a front-end for a permissionless Dune Analytics-like service, a natural-language search engine, and many other demanded use cases.Furthermore, we expect developers to use the SQL query feature for the development of APIs on top, and in general for more advanced aggregations on the client side.
The implementation - We have no intention of making the SQD network to be computationally heavy. Instead, the network must provide developers with primitives that can allow for more sophisticated computations on a higher layer of the stack. In line with this philosophy, the SQL functionality will likely be built by breaking queries down into smaller pieces, which can each be executed by workers. Another alternative is that a bulky part of these aggregations will be carried out by the Gateways.
Likely, it’ll be a combination of this. Time estimate - We are still at the research phase in the development of this feature, and we expect its release to be non-linear. The first minimum-viable implementations may become available in Q2 2025.
Decentralized Dataset Provision
Status quo - The network currently depends on Cloudflare R2 as worker nodes’ main source of data. Further, there is no way to see or verify on-chain the status of the work done by worker nodes. The goal - Replace R2 as the data source for worker nodes with a decentralized mechanism and ensure the on-chain accessibility of metadata about the inner workings of SQD Network.
Value unlocked - As a result of this implementation, data will always be able to enter the network, no matter what, in a permissionless manner. This unlocks better distribution for the data itself, and the ability for the community to validate information about the data contained in the data lake (i.e. how many blocks have been indexing, when this data was provided), further improving the trustlessness of SQD.
The implementation - We will develop a series of smart contracts and a more sophisticated query engine on the worker side. Data will be stored using a decentralized storage provider (likely IPFS). The way it works will be as follows: The data provider puts data into the decentralized storage, creating a transaction on-chain which describes the data. Whenever a new piece of data is submitted, an update will be transmitted to the smart contract so that the workers know that the data is there.
Time estimate - Smart contracts will be deployed, and the R2 dependency should be eliminated by Q4 2024. The first data providers may begin to be whitelisted in early 2025. Eventually, whitelisting of data providers will likely be transferred to the community, and will be carried out through token governance.
Light Squid Indexers
Status quo - By default today, squid indexers send data to postgres databases, which are heavy and hard to replicate. As a result, builders of squids are forced to use centralized production environments as hosting, including SQD Cloud. While the SQD mainnet launch made great progress towards decentralizing the ingestion Web3 data, and at making this data available in an efficient in P2P manner, it has not so far provided a way to transform and present this data as APIs in a decentralized way.
The goal - With the introduction of Light ‘Squid’ Indexers, Subsquid Labs will introduce a decentralized way to serve APIs with maximum performance improvements over legacy protocols (i.e. the Graph, SubQuery). The light indexers will serve as fully decentralized back-ends for decentralized applications that are both easy-to-run, provide validated data in real-time, and scale with increasing usage.
Value unlocked - Light squid indexers will enable very low-latency data for end users. Replicated on an AVS, they will offer unlimited scaling and will be rapidly forkable and deployable in different regions, offering additional performance improvements. For certain use cases (for example when privacy for aggregated data is of the utmost importance), light squid indexers could be deployed on the device or in the browser of the end user.
The implementation - Inspired by recent advances in database replication technology (such as the recent implementations of Turso), we will begin by making squids natively compatible with SQLite, in lieu of the very bulky Postgres. For initial testing, these light squids will be deployed to the cloud service, enabling current users to be able to fork their existing indexers in order to make them available in multiple regions. This is a product that has been demanded for some time.
Once light indexers on their own are production ready and tested, we will begin to deploy them on decentralized rails. Since SQLite is light, it can easily be run on an AVS. We are currently deciding on the best platform for SQD and weighing the pros of and cons are all popular staking layers, including Eigenlayer and Karak.
Time estimate - The first viable light indexers will begin to be tested for production usage on the Cloud in September 2024. Multiple-region forkability should go live soon after. We intend to migrate light squids to an AVS towards the end of Q4 or the start of Q1 2025.
Community Call to Action: Provide Feedback
Upon reading this article, we highly encourage anybody knowledgeable in the areas we are building to provide their suggestions, comments, and criticism. The best possible place to do this is in the SQD Discord. Feel free to @ an Admin. We are looking forward to your feedback.