How does Subsquid index data so fast?

In the rapidly evolving landscape of Web3, efficient storage and data availability are a cornerstone for innovation and growth. In a world where the amount of on-chain data is not only increasing exponentially, but also is becoming more and more fragmented, old solutions are not enough anymore/don't suffice anymore. This is where Subsquid redefines expectations and sets a new bar for speed. In this article, we dive into the intricacies of Subsquid's technology and explore how it achieves its remarkable indexing speed. ?
A part of the answer lies in how Subsquid stores data in a decentralized data lake.
Decentralized Data Lake: The Subsquid Network
First, we'll look into how the blockchain data is stored. Subsquid uses a peer-to-peer data lake to store Web3 data. The Subsquid Network, is infinitely scalable. New nodes can join the network without any barrier for entry. The chains act as data providers and the data is compressed and distributed among the network nodes. Each node is responsible for a certain subset of blocks.
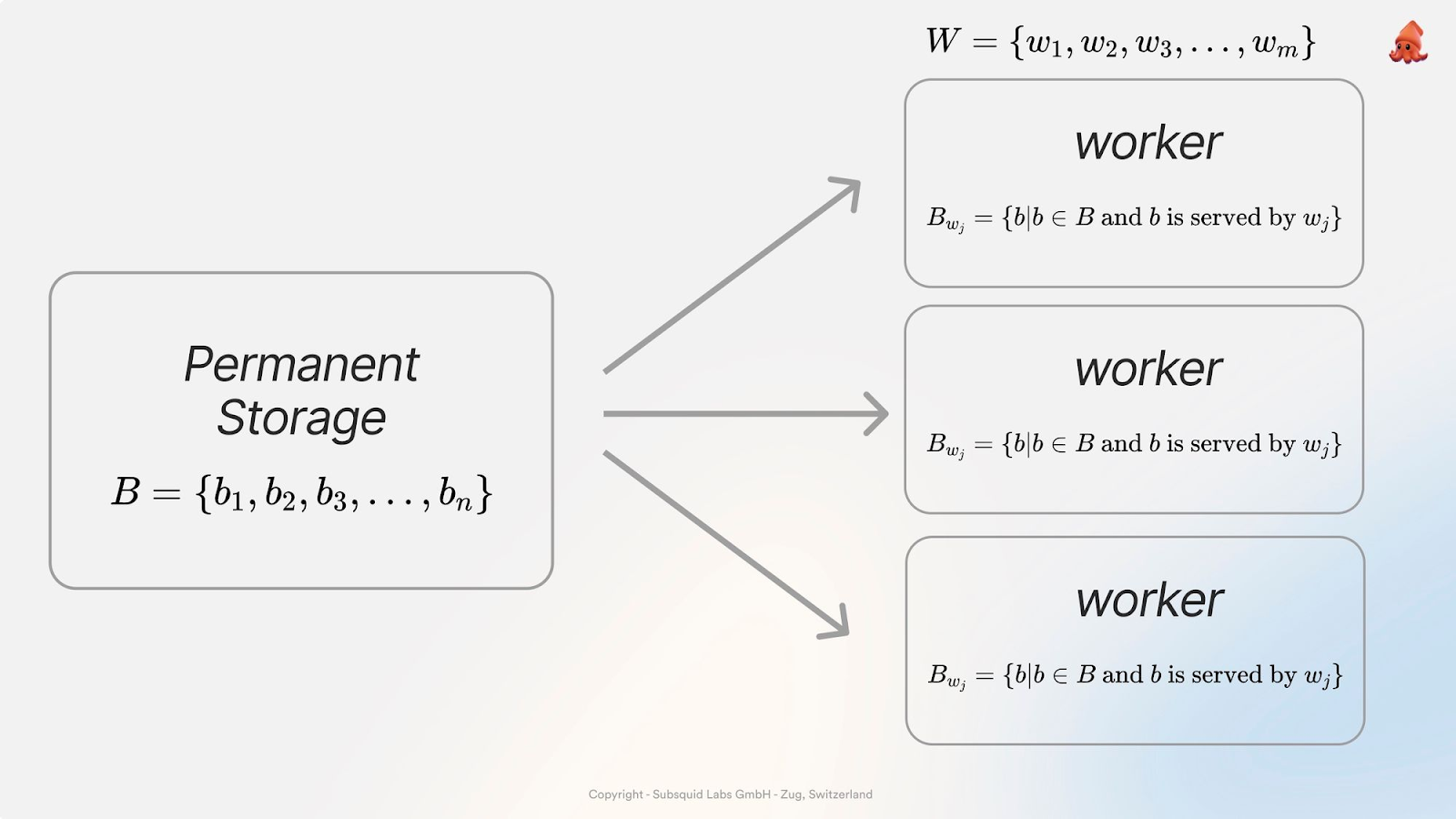
Data Retrieval Mechanism
The secret of Subsquid's speed lies in its data retrieval process, which is both quick and straightforward:
- Archive Height Determination: The process starts by determining the height of the archive, which is crucial for locating the data.
- Worker ID Acquisition: Subsquid then retrieves the worker ID corresponding to the start block of interest.
- Querying the Worker: Once the appropriate worker is identified, the system queries it for the required data.
- Iterative Retrieval: This process is repeated until all blocks within the desired range are retrieved.
Under the hood, a libp2p finds the desired worker using one of the available discovery mechanisms, connects directly to the worker and downloads the data chunk. This method is a significant departure from traditional RPC methods, as it allows the retrieval of multiple blocks at once, substantially speeding up the process.
This is how it would look like directly from the terminal:

Granular API for Selective Data Retrieval
Another notable feature of Subsquid's network is its granular API, which allows users to request specific data fields from a block, eliminating the need to download the entire block. For instance, if a user needs transaction details for a specific address, they can request only the required fields such as hash, input, and gasUsed for the block. This selective approach minimizes the data processing load, making the system more efficient.
Let’s look at this example, where we request transactions to vitalik.eth with hash and input fields.Additionally, we request gasUsed field for the block. This is the only data we are going to receive, minimizing the need for processing

And here’s is an example of the response: IMG

Squid SDK: Enhanced Flexibility and Functionality
Building upon the strengths of Subsquid's data retrieval mechanism, the Squid SDK offers even more flexibility as well as out-of-the-box solutions:
- Indexing Hot Blocks: The SDK facilitates real-time indexing of new blocks, keeping the data up-to-date.
- Automatic Handling of Reorgs: It adeptly manages blockchain reorganizations, ensuring data integrity and continuity.
- GraphQL API Integration: The SDK provides a ready-to-use GraphQL API, making it easy to integrate with decentralized applications (dApps).
- Versatile Storage Options: It supports various storage solutions, including local or external storage, and formats like Parquets or CSVs.
- Real-Time Data Access: By integrating an RPC endpoint, the SDK allows for real-time data interaction, vital for applications requiring up-to-the-minute data.
Conclusion
With this approach Subsquid changes the game in Web3 data management. It combines decentralized storage, rapid data retrieval, and a detailed API to effectively manage the growing complexity of blockchain data. The Squid SDK adds even more value, offering real-time data indexing and a variety of storage solutions. This technology stands out for its ability to index blockchain data up to 1000 times faster than traditional methods like subgraphs. This remarkable speed and efficiency make Subsquid a go-to tool in developing decentralized applications.
Subsquid Website | Documentation | GitHub | Twitter | Developer Chat
Written by Daria Agadzhanova, DevRel @Subsquid