Solving the Blockchain Trilemma with Modular Data Tools

Up until last year, a majority of blockchain activity happened on mainnet. However, this year, many transactions have moved to L2s, which sometimes make up 5x the volume on Ethereum.
This trend has come with a shift in how we think about blockchains, from building monolithic chains to creating a modular future.
But let's take a step back and examine what holds blockchains back, namely the blockchain trilemma.
What’s the Blockchain Trilemma?
The biggest challenge blockchain developers face is the blockchain trilemma. It states that a given blockchain can only achieve two out of the following three properties:
- Security: can a network defend itself, and how hard is it to attack
- Decentralization: no single point of failure, vast network of nodes
- Scalability: can the blockchain handle a growing amount of transactions
Ethereum, for example, is considered decentralized and secure but struggles to keep up with increased demand. Other networks have increased scalability but have sacrificed decentralization, as most improvements in scalability have been achieved by increasing block space or decreasing validator count.
The blockchain trilemma assumes monolithic chains.
The problem with monolithic blockchains
Monolithic chains are blockchains that handle all of the core functions of a blockchain in one layer. These functions are:
- Data Availability: this layer ensures that the blockchain transaction history is available for verification and confirmation that any state changes are valid.
- Execution: this layer is where transactions and state changes are initially processed. It's also the one users interact with when signing transactions, transferring funds, or deploying smart contracts.
- Consensus: this is where the nodes agree on which transactions to process their order and enforce compliance with consensus rules.
- Settlement: on this layer, transactions are committed to the ledger and, after a specified amount of block time, considered final.
Having all these functions in one layer obviously has benefits, such as security, utility by focusing on particular use cases, and simplicity for builders. Yet, the drawbacks have also become evident with monolithic chains making trade-offs in the trilemma - usually trending toward increasing centralization and having ledgers that grow infinitely, making it harder for new nodes to join the network.
But what if all the blockchain functions don't have to be handled by the same set of nodes and layers? In a nutshell, this is what the modular blockchain thesis is about.
Modular blockchains
Modular chains take apart the core components, allowing for optimizations to individual layers and improving the overall system. The modular thesis has taken off because of the introduction of fraud proofs and data availability sampling, which make it possible to verify the state and continue scaling a network as new nodes join.
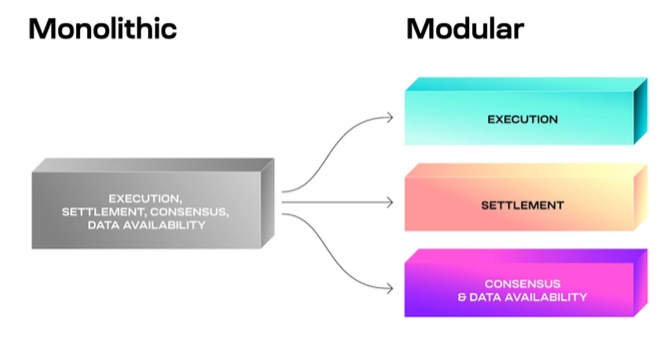
When building in the modular paradigm, developers no longer have to worry about each function but can focus on one and outsource the rest to other layers. Rollups are a great example of how modular blockchain can look like.
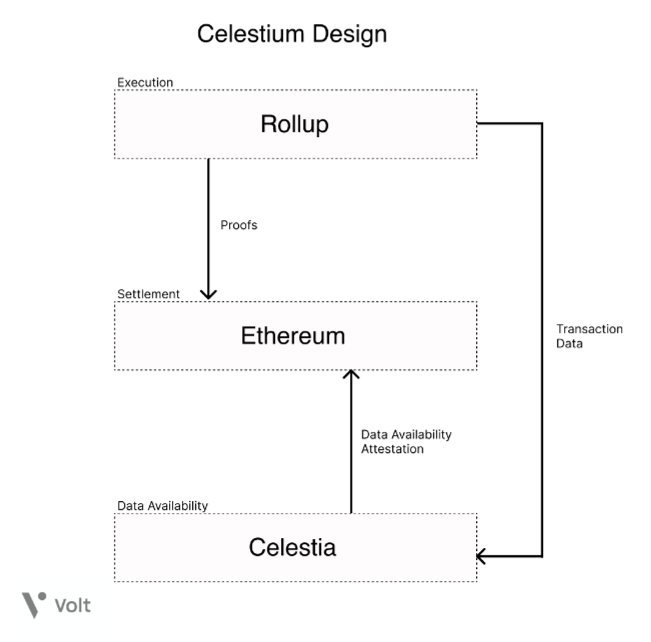
Rollups sit on top of Ethereum and function like an extension to it. They handle computation and use fraud proofs to submit proof that what they computed was correct. Additionally, they rely on Ethereum for Data Availability.
Since Ethereum is expensive, 90% of some rollup costs are spent on posting to Ethereum mainnet. Even though zk Proofs can further compress the data, publishing to Ethereum remains costly. This has led to the creation of Validums, a type of rollup where a network of POS validators stores data off-chain.
Many of the modular blockchains are focused on offering Data availability to reduce these costs. The first modular chain, Celestia, provides builders with data availability, offering an alternative to posting data to Ethereum for Rollups. Below is an illustration of how such a setup can look like.
Other examples of data availability layers include Polygon Avail and EigenLayer.
Beyond data availability, some providers, such as FuelVM, also specialize in optimizing execution.
The benefits of modularity include:
- Scalability: the trilemma is effectively solved by splitting tasks across layers. Rollups increase scalability while maintaining security thanks to the underlying chain. And with Data Availability Sampling, the system can scale without exponential growth of workload.
- Ease of launching chains: with a modular blockchain stack, it's easier for developers to launch new chains or rollups. Take Eclipse, where SolanaVM runs on top of an Ethereum rollup that relies on Data availability from Eigenlayer. The overhead and time to launch are drastically reduced.
- Flexibility: modular layers are highly flexible and can be adjusted or changed as needed. They also promote interoperability between chains and layers.
Nevertheless, while splitting functions is great for scaling chains and allowing customization, it also comes with challenges regarding security and complexity for builders trying to develop dApps.
Fortunately, a crop of next-generation web3 infrastructure projects offer solutions for modular chains, and dApps are building on top of it.
The crucial component for any dApp is data.
Storing data
Often, dApps have a vast amount of data that needs to be stored off-chain. This can include metadata for NFTs or the text that is published on decentralized blogging platforms.
The most commonly used platform for resilient data storage is IPFS, the interplanetary file system. The p2p network relies on content addressing to identify files and connect all hosts, who tend to be individuals or businesses. However, because there is no incentive mechanism nor quality control in general for gateways, it can lead to content being unavailable temporarily and hard to find. It's also challenging to get started using it more commercially.
Next-gen data infra for storing and serving data
Despite challenges arising from individual use of IPFS, it remains an attractive option for file storage. It allows for smooth operations when used with reliable gateway hosts and tech.
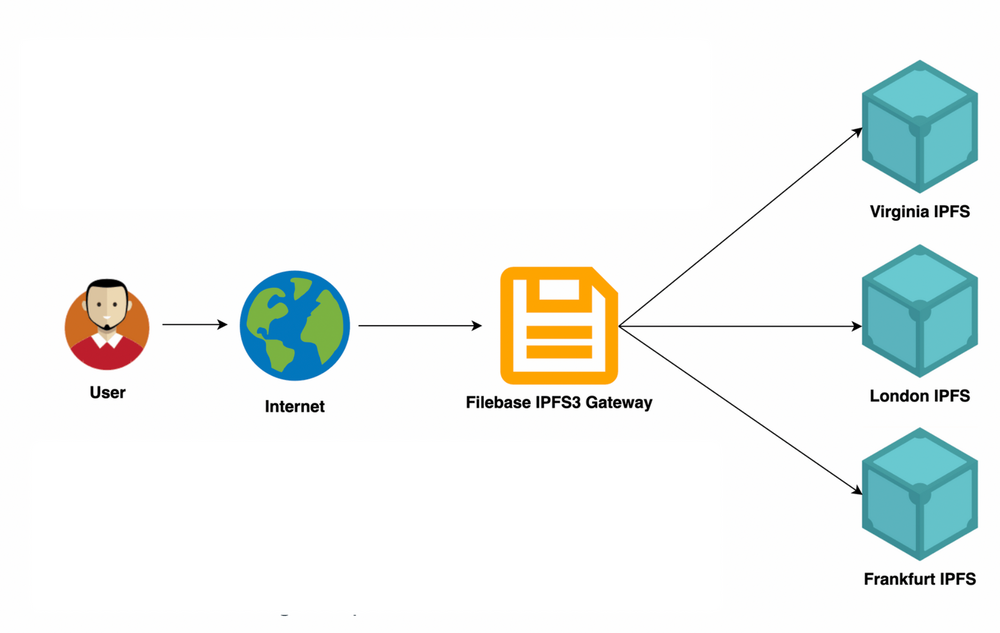
{kind=link}
Filebase and Crust Network are companies dedicated to enabling devs to store data on IPFS without dealing with the usual complexity. Filebase offers a way to pin data to IPFS and leverages edge caching to ensure data is served readily. Crust Network provides a cloud solution for Web 2 and 3 companies by adding an incentive layer on IPFS. Currently, its capacity sits around 1,200 Petabytes.
Other database projects like Kwil DB are focused on enabling the creation of byzantine fault-tolerant networks that will serve dApps and web3 services with resilient, highly customizable storage.
Lastly, IPFS isn't the only decentralized storage that web3 projects rely on. Increasingly, builders are choosing Arweave, a blockchain specialized in indefinite data storage. WeaveDB, a decentralized NoSQL database, runs on top of Arweave and facilitates interactions with it by providing a web2-like developer experience.
Storing data isn't the only activity dApps need. The next step is writing to the data and ensuring that user changes are reflected.
Making Changes
Developers rely on RPC to trigger state transitions or any interaction with an underlying blockchain. RPC is a protocol in distributed computing and facilitates communication between nodes. It also serves as a bridge between components and handles tasks like sending transactions.
In the modular blockchain landscape, RPCs must adjust to serving requests requiring access to more than one layer or chain. Pocket Network and Lava Network are both examples of networks that have made it their goal to offer decentralized RPC access for web3 projects.
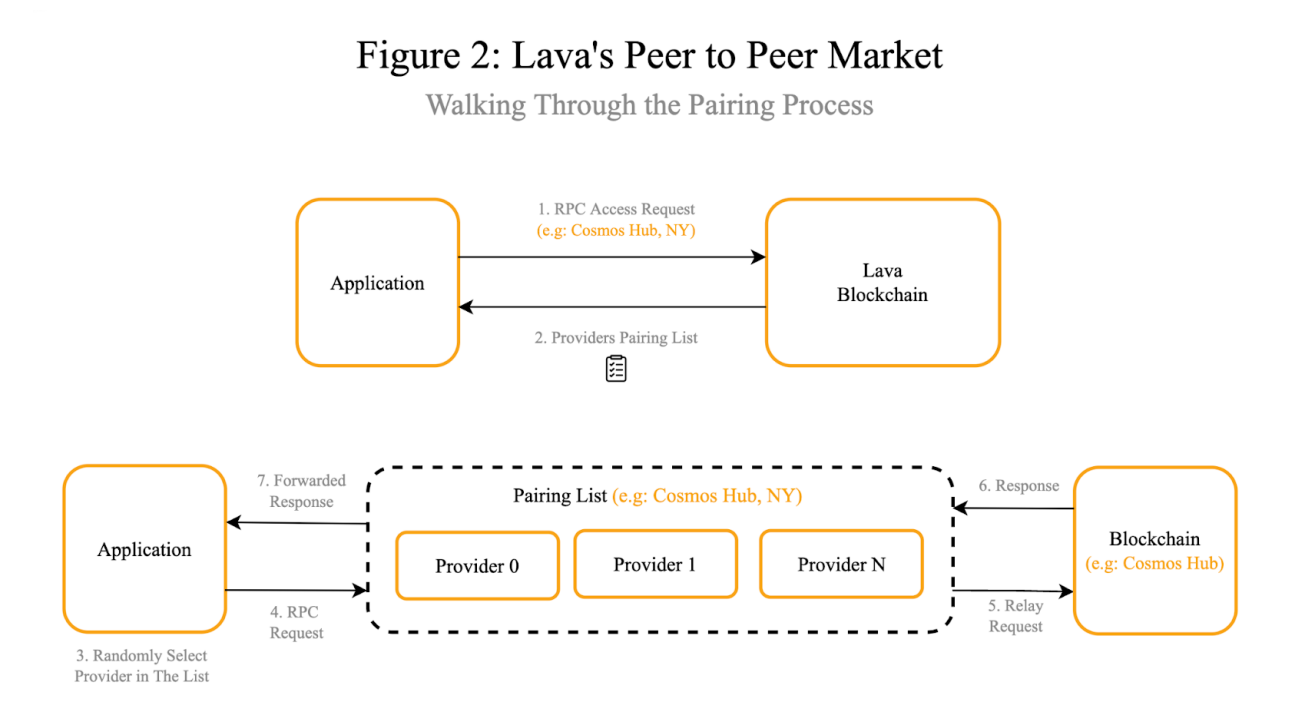
Instead of relying on a centralized provider to relay calls dApps will access a gateway that interacts with a network of decentralized nodes that route requests as necessary to nodes in the relevant networks.
The more blockchains these decentralized RPC networks integrate, the more easily developers can access a wealth of chains without integrating them individually.
After storing and making changes to data, the only remaining piece is getting the data.
Data is fragmented across blockchain ecosystems and layers in a modular blockchain landscape. It's also partly stored off-chain, yet necessary for apps to function. Take NFTs; without the metadata, there is no image to show to users.
Indexing
The key to using on and off-chain data is indexing. Indexers take in all of the blockchain data and serve it efficiently. Subsquid is a full-stack blockchain indexing solution that gives builders all the data they might need through a comprehensive SDK.
By aggregating all the data spread across Layer-2s, different modular chains, and from decentralized storage solutions, Subsquid tackles the data access problem and makes it easy to work with large amounts of data through its specialized data lakes. While the decentralized network is currently in testnet, it already powers dApps totally well over 11 billion dollars in value.
In conclusion, the industry is shifting from a monolithic to a modular paradigm, where it's not one chain fulfilling all the functions but a stack of layers combined for an optimal experience. Navigating this modular landscape appears challenging initially but is drastically facilitated by next-generation web3 data infrastructure projects that enable developers to store, read, write, and access data across chains and networks.
The future is modular, and next-gen data solutions like Subsquid are paving the way for builders to tap into the wealth of data generated.
Docs | GitHub | Twitter | Developer Chat
Article by @Naomi_fromhh