SQD Network Architecture explained

On September 25th, SQD CEO Dmitry Zhelezov went live on a X Broadcast to explain SQD’s network architecture in-depth.
Let’s not sugarcoat it, most people haven’t read the whitepaper, and the only ones who ask about the actual architecture, tend to be developers - as Dmitry is quick to admit.
Still, there’s a value in understanding how things work, especially, when they could become a data backbone of web3.
“The noblest pleasure is the joy of understanding.” - Leonardo da Vinci.
If you’re ready to embark on the noblest pleasure, and missed the broadcast, read on to learn about SQD’s architecture.
You can also watch a full recording here:
Why SQD?
As every business coach’s favorite Ted speaker Simon Sinek once said: Start with Why. That’s what keeps people going, after all.
So why SQD?
That’s a great question, and on the technical side it’s easily answered by looking at the state of data in Web3.
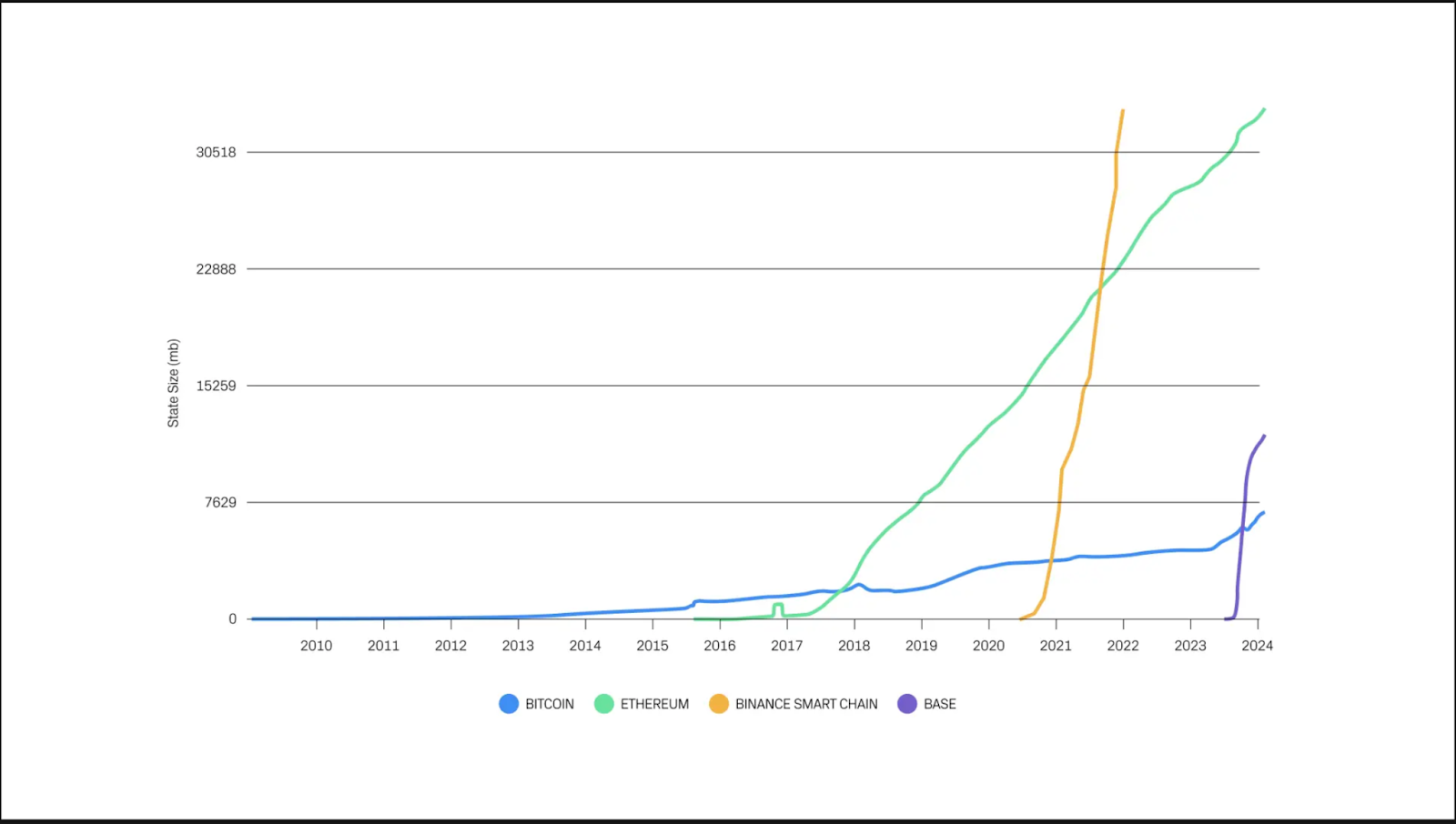
As the visual impressively illustrates, Bitcoin’s growth is fairly linear, whereas chains like Ethereum, BNB and Base have seen their state grow exponentially.
The sheer scale of data makes it difficult to access. Yet, that’s not all there is to it. While this graph just includes four chains, there are now countless Layer-1s, Layer-2s and even some Layer-3s in the space. More chains -> more data. And data is fragmented across these ecosystems.
For now, builders have mostly tapped into blockchain nodes to access data. But these nodes aren’t optimized for handling data at scale, but to execute transactions and come to consensus.
The solution?
A separation of execution, consensus (this remains responsibility of blockchain nodes) and data access (SQD).
When all the onchain data is aggregated in SQD, it becomes a data ocean that allows anyone to access data without needing to put up with the constraints of blockchain node infrastructure.

What SQD isn’t
Although SQD deals with onchain data and making it accessible, it’s important to highlight what SQD isn’t.
- It’s not a Data Availability Layer like Celestia. Those are responsible for storing L2 data, and making it available to aid consensus and execution.
- It’s also not a decentralized storage solution. While we do rely on a storage provider as part of oursteps, SQD is really more of a distributed database for petabytes of onchain data. Not a place to store your meta data, or files like Arweave or IPFS.
SQD is..
A platform that provides access to onchain data, a query engine for granular filtering which is important for running indexers, all while providing crypto economic guarantees of data validity,
“There’s no difference in validity between running your own blockchain node to get the data and using SQD to access it.”
Solving the onchain data access problem leads to better developer experience, and by making it faster, and scalable to retrieve data across chains - serves as a foundation for dApps with better UX.
Lastly, it contributes to decentralizing the whole stack, rather than just a few select pieces of it.
The Data Flow in SQD

The best way to envision how SQD works is by looking at how data flows through the network. The first step is a process that retrieves onchain data from the blockchain. Then this data is packed by the ingester into parquet files - a special format optimized for querying - and added to permanent storage.
For now, permanent storage is hosted by a centralized provider, but it’ll be decentralized over time to use options such as Arwaeve or IPFS.
From there, it’s easy to extract the data. Worker nodes are assigned pieces of data to store. To ensure redundancy, each range is replicated across multiple nodes.
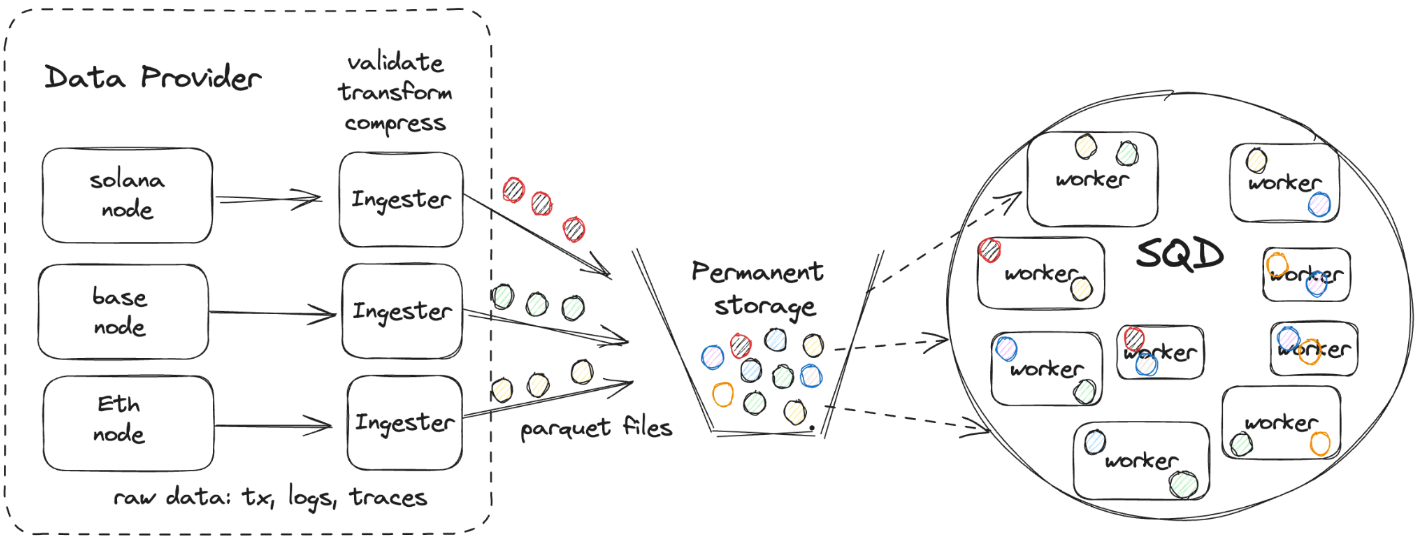
In essence, each worker node is a mini API, that serves data stored in local cache, making the network as a whole one of thousands of API servers serving different ranges, covering the entirety of onchain data of supported chains.
Querying
The key promise of SQD is to provide permissionless, open data access. Anyone can query the data, all they need to do is run a special piece of software, a light client, that coordinates their request with the network. This client is called portal and directly connects users with the worker node that has stored the data they request.
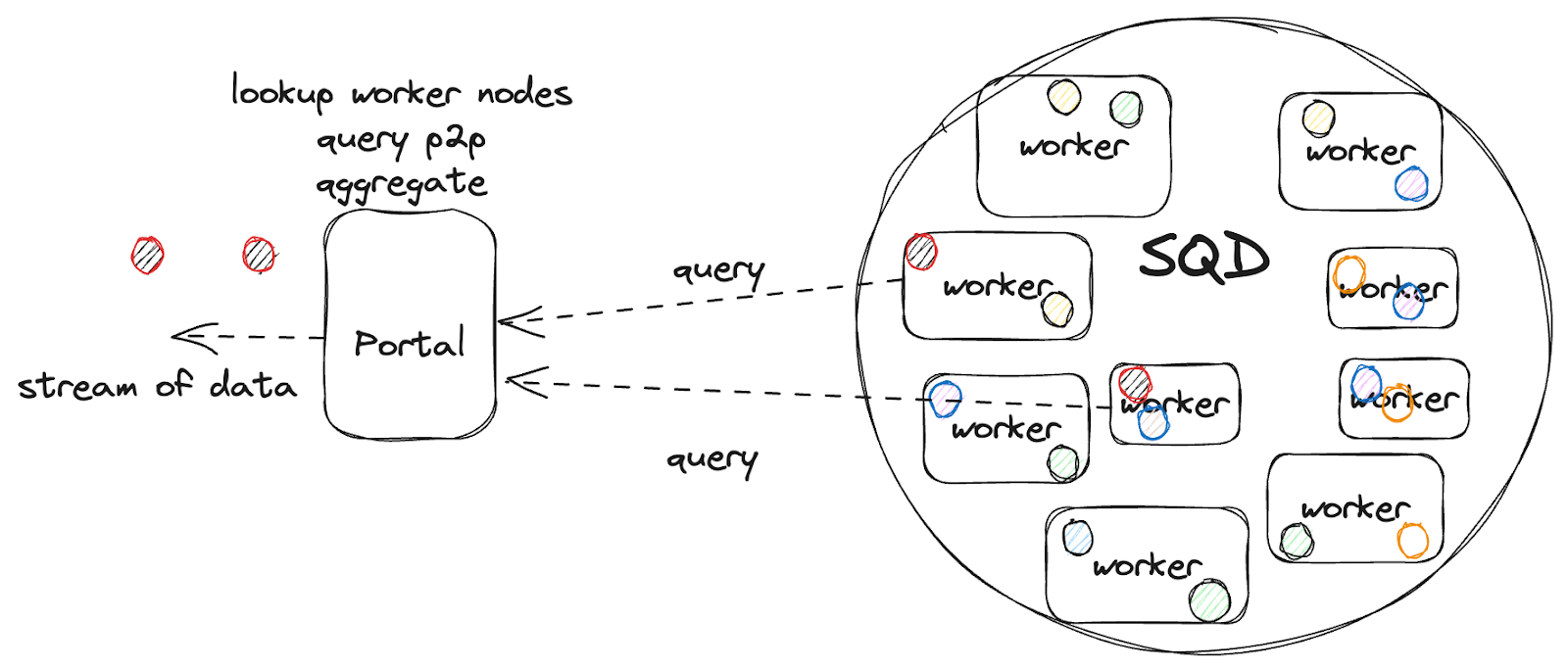
It functions similar to a Bittorrent or IPFS client which knows where to find the files you have stored. How much data you can stream depends on how much SQD tokens you have locked, ensuring that the network wont’ be abused.
And the more data is needed, the higher the demand for SQD tokens will be.
Note, the Portal is set to go live later this year. Currently, connections to SQD network are facilitated via Gateways, but the core principle is the same. Portals just unlock much faster, accessible ways to use SQD.
If you want to be among the first to try the upcoming release, get in touch with the SQD team.
Lastly, Dmitry also addressed the question of speed.
How does SQD achieve magnitudes faster indexing speed?

The faster data can be indexed and made sense of, the faster it can be displayed in the user frontend, meaning, speed increases matter quite a bit for Web3 dApps.
SQD is up to 100x faster than relying on RPC nodes for access, and decentralized indexing protocols like The Graph. But how?
A major innovation implemented are parquet files, designed for efficient extraction of data.
“A gamechanger for retrieving data.”
In addition, SQD leverages a distributed network of nodes to deliver faster streams. Usually, when connected to one endpoint, there’s a limit to how fast you can get data.
However, SQD enables the parallelization of endpoints, since data is stored in ranges across different nodes, meaning your bandwidth multiplies.
The only constraint then becomes your internet connection.
Another piece contributing to speed is modularity, separation of the data ocean which serves the data, and the tooling on top that allows working with and building full end-to-end pipelines.
Once data has left SQD, developers have full control over how to use it.
Thanks to everyone tuning in for the livestream. Let us know if you’d be interested in seeing one where we break down the SQD economics.
And for early access to the first portal releases, get in touch.