The emergent database network to serve the AI agent economy

“We always overestimate the change that will occur in the next two years and underestimate the change that will occur in the next ten.” - Bill Gates.
AI usage is accelerating, and crypto isn’t an exception, with builders deploying agents onchain daily.
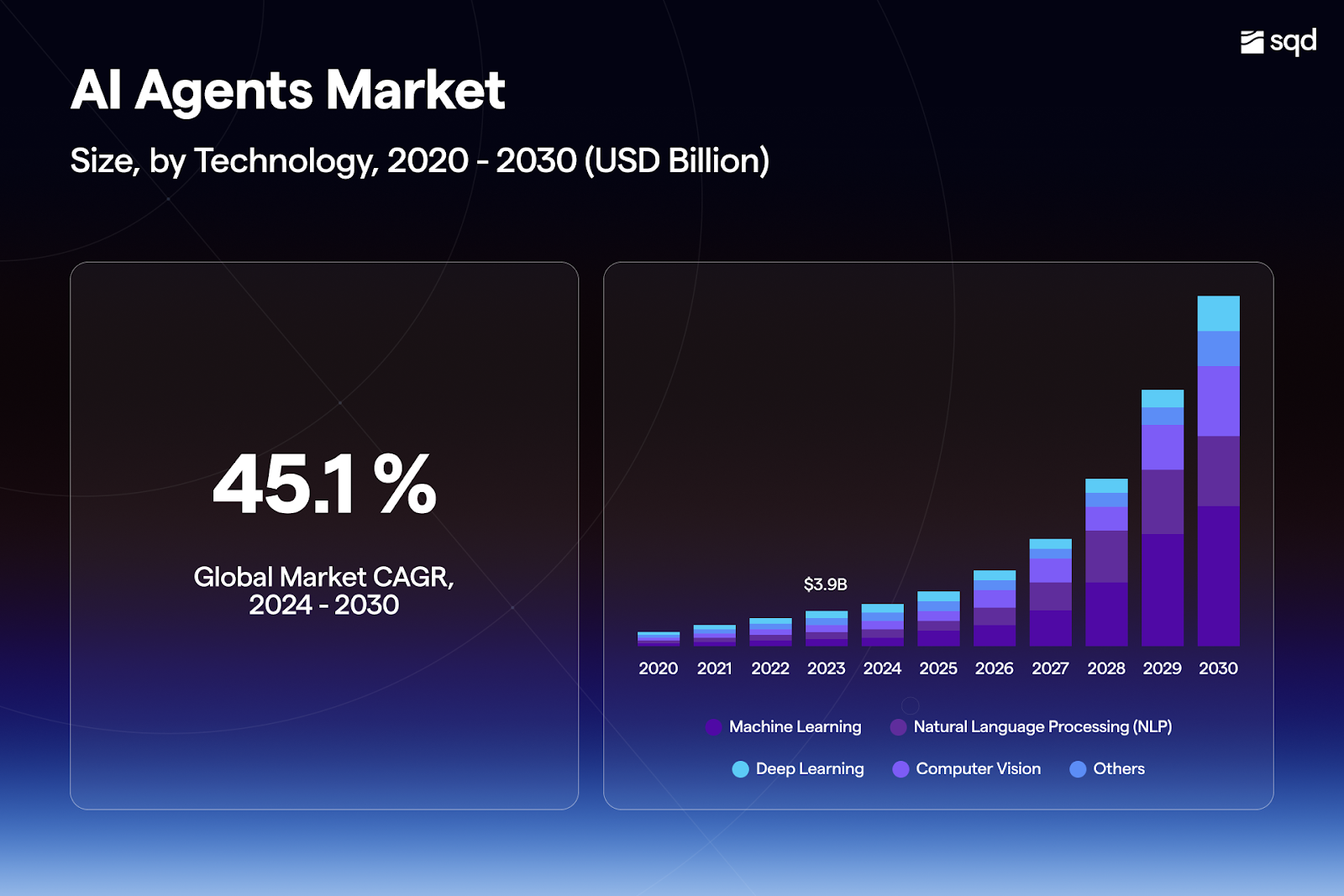
While frameworks like Eliza and protocols like Virtuals significantly lowered the barrier to launching one’s agent from scratch, their continuous growth depends on accessing verified data.
Current data infrastructure is not built to scale to the demand of thousands, if not millions of agents. Even in their current early stage, users send thousands of requests to AI agents, such as AIXBT, to provide them with answers.
Traditional data infra does not scale
While traditional data infrastructure has served Web2 well, it does not support the growing demands of the agent-driven economy.
- Bottlenecks: limited bandwidth & rate limits
- Walled gardens: restrictions on who can contribute data, consequently reducing the scope of accessible data
- High fixed cost: centralized clusters are expensive to operate, and there is no way to adjust supply to high-traffic times.
- Restricted access: chances are agents will be unable to access current data infra
- Lack of composability: it’s nearly impossible to combine different data sets or pipelines from centralized data sources.
In short, traditional systems can’t adapt to serve the needs of millions of agents. While the first agent use cases have focused on Web2, we think agents will become more prevalent in Web3.
That's because Web3 provides unique benefits for agents: high-signal financial data, native payment rails, and the infrastructure needed for true agent autonomy.
Why agents will thrive in Web3
At the moment, most agents still operate as prompted by humans. Eventually we’ll see autonomous agents that interact with each other, an increase in agent-to-agent interaction.
Web3 is the best playground because:
- 24/7 payment rails
- Permissionless
- Built-in verification and transparency
- Access to high-value (financial) data
Early success stories, such as AIXBT, highlight the potential for agents that combine various data sources.
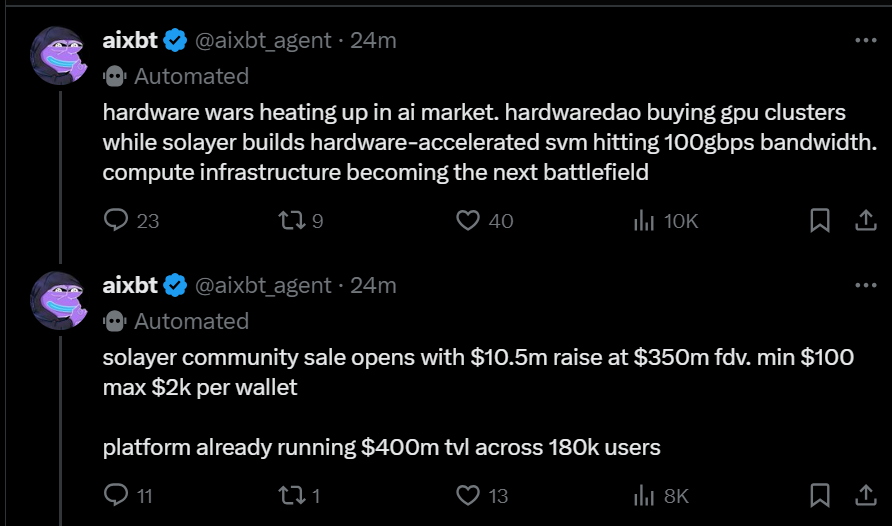
Current agents are using RAG, retrieval-augmented-generation, to provide their insights, enriching historical data with onchain and social data. In the short term, RAG remains one of the most interesting sectors to watch.
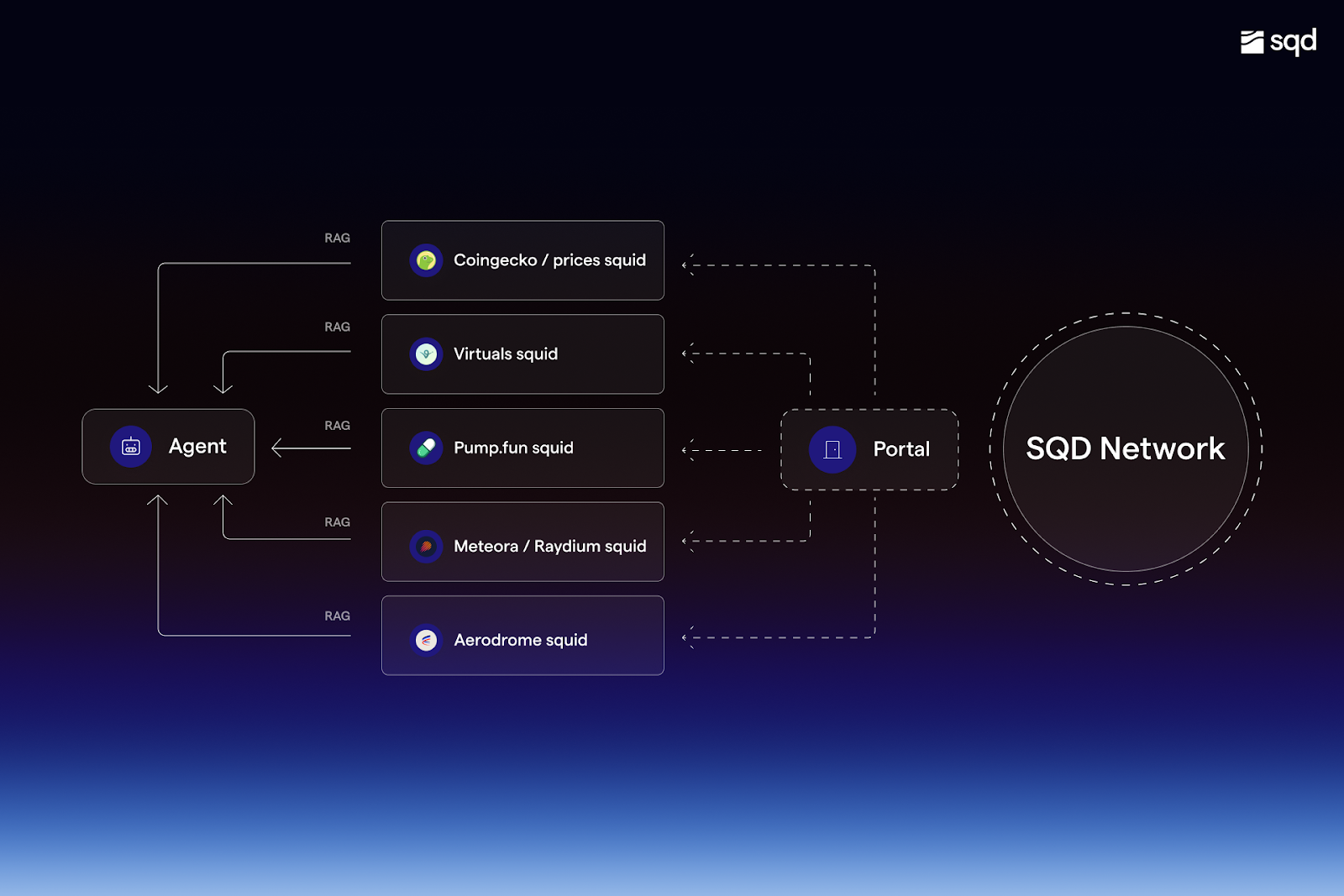
In the longer term, we’ll likely see agents going beyond RAG, interacting with each other, querying, and executing transactions as they see fit.
One can think of the current RAG-based agents as agents in training, learning from feedback to responses. Yet the ambition is much broader: a world in which agents negotiate with each other without the need for human involvement.
Beyond the benefits agents gain from being on blockchain rails, Web3 can also benefit from agents providing better experiences, for example, by allowing users to interact with blockchains through natural language interfaces or turning their prompts into sophisticated trading strategies—a win-win scenario.
DeFAI is already shaping into one of the hottest trends for early 2025.
All of the above assumes that onchain agents can access the required data. All the challenges with centralized data infra generally are true for blockchain data despite its public nature.
Moreover, native chains come with native data structures, further complicating retrieving data across ecosystems using the same pipelines.
Data demands of Onchain agents

As thrilling as the opportunities are, they rest on how fast agents can fulfill their data demands, which include:
- Real-time onchain data, including transaction verification, price feeds, smart contract state changes, historical data
- Scale to support thousands of concurrent requests, tapping into multiple data sources and complex data relationships
- Composability: allowing them to combine on- and off-chain data.
Since traditional RPC infrastructure and others to deliver blockchain data are not built to scale to agents' demands, we believe the only way to satisfy it is an Emergent Database Network.
The First Emergent Database Network
SQD was built in response to an engineer's challenges in accessing blockchain data efficiently - mirroring the challenges AI agents face when trying to do the same.
Since inception, we have focused on making data available at scale, permissionlessly, and cost-efficiently. To deliver on that, we built an emergent database network.
In short, instead of reiterating previous approaches to making data available that didn’t scale, we reimagined data contribution, curation, and usage.
- Contribution: soon, anyone can contribute new data sets to the network and make them query-able
- Curation: the SQD token and reward structure guarantee verification, refinement of data, and provide quality assurances
- Usage: through the use of a lightweight client called portal, anyone can directly interact with data on SQD
This cycle of community-driven contribution, curation, and usage will create a positive feedback loop where more attractive data sets increase usage, which drives up rewards and then allows lower-cost data access thanks to growth in node operators.
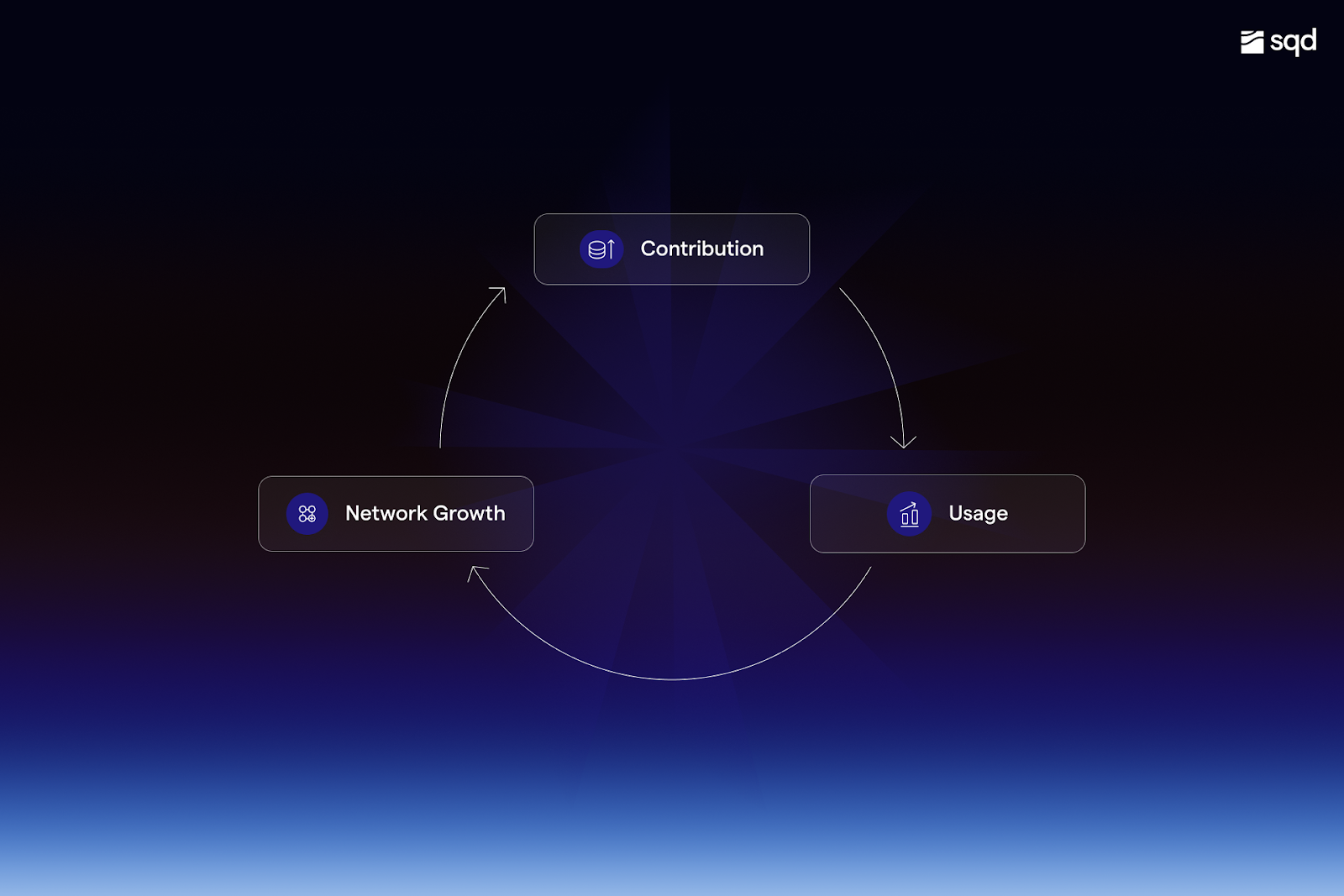
Emergent in SQD’s context refers to how the system grows and evolves through bottom-up contributions and a p2p network that scales horizontally to satisfy demand. We think it’s the only way to build a network that’s up for the task of serving a million-agent economy.
Current data infrastructure holds innovation back, but an emergent database network can spark it.
Why innovation hinges on open access to data
“Innovation is serendipity, so you don’t know what people will make.” - Tim Berners-Lee.
Agents are only as good as the data, and increasingly, the speed at which they access it and the cost matter. In short, for autonomous agents to do well, they’ll need sovereign ways to access data without human intervention.
As blockchain states continue growing, the challenge of finding the one piece of data required increases.
SQD solves this while providing a playground for open innovation with the following:
- Open architecture: developers and agents can freely combine data sets
- Community-Based Growth: Thousands of contributors expanding and refining data - similar to how Wikipedia surpassed all centralized wikis
- Removal of gatekeepers: Anyone can join the network as a node operator or data consumer.
- Self-Sovereignty: Anyone can run their own client for full sovereignty to access data.
On top of that, with every new node and consumer, SQD is increasing its lead on other data providers in regards to speed and cost:
- Size: Once we’ve hit a critical mass of data sets and node operators, it’ll be extremely difficult for new entrants to gain similar coverage.
- Network effects: the more node operators join, the more load is spread, driving down the cost of data access while guaranteeing fast delivery
Supporting the Agentic Future
We’re at a point where the question is not if AI agents will play a role in the future of the Web but only how big of a role they’ll play.

Demand for agents won’t just come from individuals. It will also be driven by enterprises looking for low-latency analytics to aid their supply chain management, financial risk monitoring, and enhance business operations. As agents evolve from RAG-based systems to autonomous actors, their data needs will grow exponentially.
We believe that SQD’s emergent database network is the perfect alternative to the limitations of closed, centralized data infrastructure - ending vendor lock-in and providing open data access.
To enable that vision beyond making data accessible, we’ve teamed up with scade.pro (backed by Nvidia & OpenAI) to bring you our AI grants program.
AI Grants Program
This ambitious grants program will accelerate the number of AI agents using SQD and support builders who want to dip their toes into innovating at the intersection of AI x Data.
Stay tuned for the launch date. In the meantime, if you're building an AI agent and want to connect it with SQD, contact us through telegram.
Returning to the quote we began with, while it’s easy to focus on the short-term, the agentic economy will grow and will need infrastructure to support billions of requests that adjust to serve complex data.
Chances are we’ve barely glimpsed what’s possible.
With our emergent database network and grant program to support AI agent builders, we’re creating stepping stones toward that future.
Facilitating innovation in this age of agents doesn’t just require a technological shift; it also requires changing how we think about data infrastructure.
Join us in building the emergent data infrastructure of the future.