What is indexing?
When we tell people that Subsquid is a decentralized data lake and query engine, it’s not often that someone immediately understands what that means. Mentioning that Subsquid facilitates indexing of onchain data also often just receives the following facial expression, except when the person is a developer.

So, in this post, we want to unpack what indexing means and why we think it’s a big deal for Web3.
In Web2, indexing facilitates a large chunk of our online interactions, from allowing Netflix to serve your movies in your language to seeing what your friends tweet about or reading emails.
But we don’t think much about indexing because things work, and why should one try to figure out what’s happening in the backend when there’s not much to be gained from it? Just ask a random person on the street if they know how DNS servers work.
During Web1 times, users had to access websites by typing in IP addresses and could navigate to others via hyperlinks. Nowadays, all it takes is a Google search.
What enabled this drastic change in usability is indexing.
With Web3 growing daily, the question is, when do we get across the current chasm of UX to “mass adoption”? We believe indexing will play a crucial role in that.
Unlike Web3, though, indexing has a centuries-long history…
A little history
The word indexing comes from the Latin index, which means “to show, indicate.”
Duncan, the author of an entire book dedicated to the index, locates the origin of the concept in the 13th century with the typical Renaissance man Robert Grosseteste. As a poet, lecturer, preacher and statesman, Groesseteste wanted to have quick access to sources feeding his knowledge. To accomplish this, he created a “Tabula” with 440 topics that covered all he knew, starting with God, where each topic referenced different sources.
It was the first index, a system that provided a quick, efficient overview of where to find what.
Nevertheless, it wasn’t until centuries later that indexing became more popular. With the invention of the printing press, book copies would share the same pagination, enabling the printing of books at scale and the inclusion of indexes.
Yet, the word index also started to gain a different meaning. Considering the influence of the Catholic Church, the first index was nothing but a list of books that good Catholics were forbidden from reading because they were immoral.

Eventually, as we lost God (at least according to Nietzsche) and the influence of religion faltered, the word index became associated with its original meaning again: of organizing and referencing information.
In the 1950s, the Belgian author and writer Paul Otlet worked on an index of literature and knowledge, accumulating 11 million entries. What’s even more astonishing is that he also foresaw the future. He described a system in “which knowledge would be projected on one’s individual screen so that ‘in his armchair, anyone would be able to contemplate the whole of creation or particular parts of it.” If that sounds familiar, it’s because we use it every day.
As computers became ubiquitous, so did the need for accessing the data we generate with them. In its first stages, the web consisted of loosely linked pages that one could only access directly via IP or by clicking from one through to another.
Then came Google, the first to index the internet and make it searchable—arguably a watershed moment for usability. The search engine has been so successful that its brand name has become a verb, and we don’t say that you’d search for something on the web, but you just Google it.
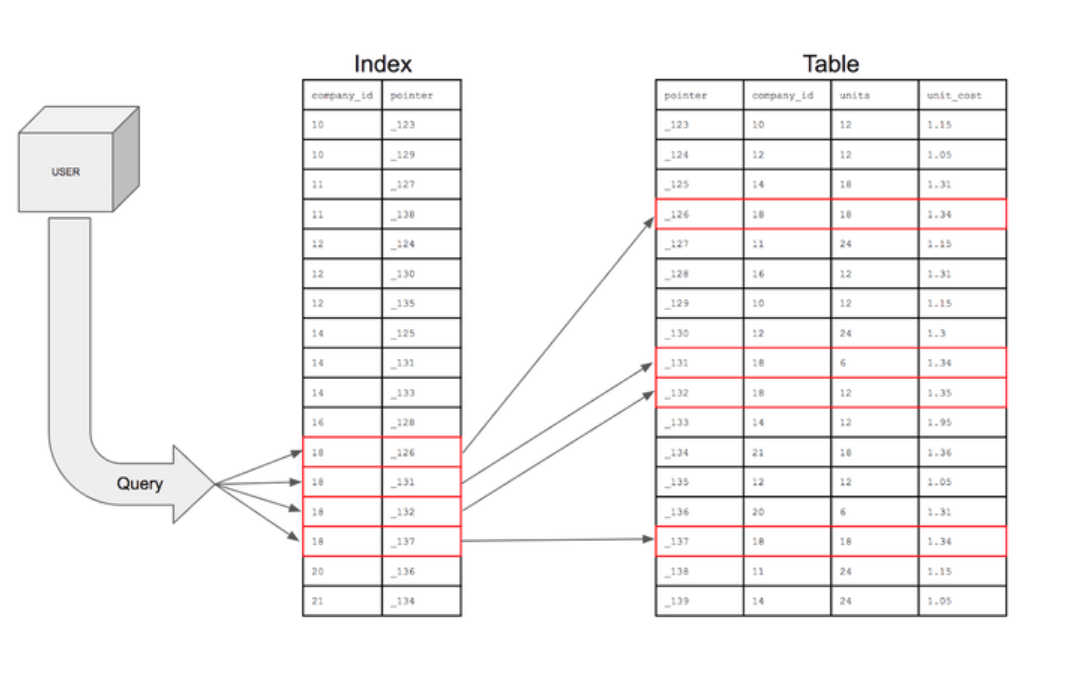
Indexing Web2 data works similarly to the index in a book: it’s the process of compiling data into more organized, readable formats. An index is then an ordered representation of the data.
That’s fairly easy to do for centralized databases and servers.
But what about blockchain?
Blockchains are nothing but distributed databases, yet they are notoriously hard to retrieve data from. Bitcoin, the first blockchain, stored mostly transaction data chained together in blocks. As long as the ledger was small, it wasn’t a tough ask to simply download the entire data and store anything a dev needs for their service in that instance.
Take Mt Goxx, the infamous exchange, which simply stored its balances and onchain data in a spreadsheet.
Over the years, Bitcoin’s ledger has grown to 0.5 Terrabyte, making it harder to replicate such a setup. Ethereum, as a smart contract platform, has grown to an even larger state size, hovering around 1 Terrabyte.
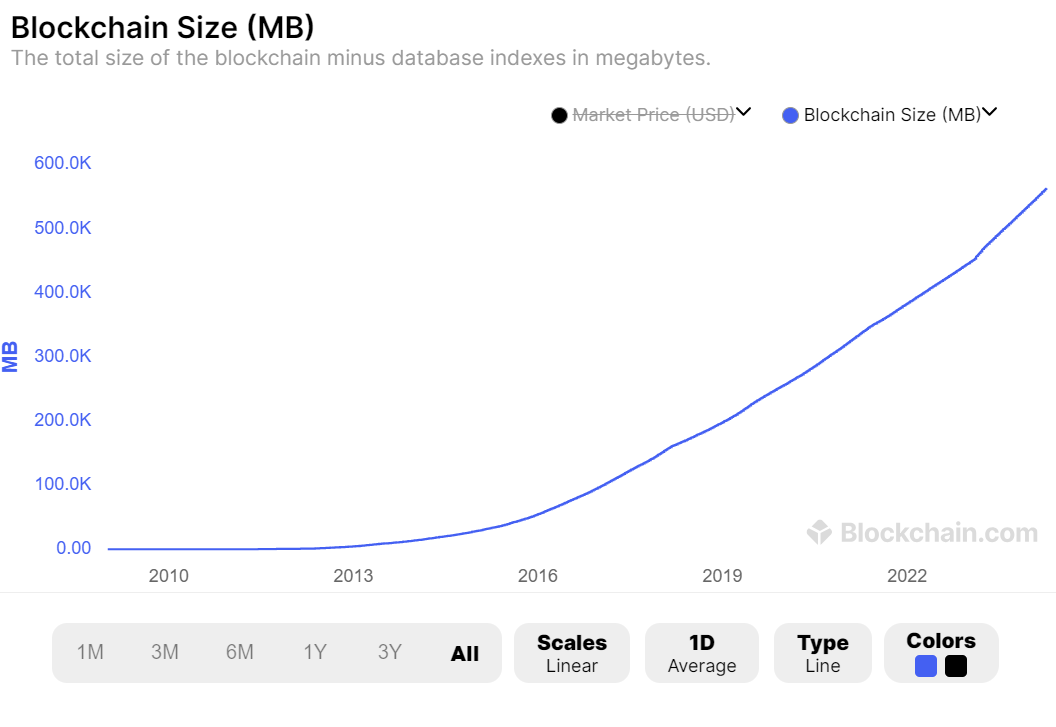
That is a lot of data that every full node in the network has to store. Since blockchains are immutable, the storage requirements know only one way: up. 📈
Let’s say you want to get access to the onchain data; where do you even go?

Onchain data is stored by full nodes. Each of these has a copy of the ledger. You just have to go and ask them for it.
The way it has traditionally been done is by using RPCs. RPC stands for remote procedure call and describes a protocol that nodes use to communicate with the blockchain. If you are an untrusting dev, this might not be an option. After all, can you trust the RPC node? You could, of course, download and compare the data from multiple nodes to make sure, but that seems unrealistic.
The solution then is to host one's own node, which is expensive (remember, you need to download that 0.5 or more terabyte and consistently keep it online) and unnecessary overhead. The alternative is relying on centralized service providers to download the data you need—in the end, this works fine as long as they are online. Yet, it makes you wonder: Isn’t it awfully inefficient that different dev teams now all download this data to store it again?
After you get the data from chains, you’ll realize it’s in raw format. The only way to meaningfully interact with the data is by putting it into a relational state.
“What you can easily do in a SQL database is impossible in blockchain, if you don’t index.”
Indexing Blockchains
Leaving aside that data in each chain is structured differently, let’s look at an example to showcase why we need to index blockchain data to build meaningful interfaces.
If you want to know the liquidity in any given Uniswap V3 liquidity pool, you need to aggregate all the information across segments. After all, liquidity is provided at different price points and tends to be highest around what’s considered the “market price.”
However, the Uniswap smart contract does not track all liquidity. It only has access to the current price. So, to find out aggregated liquidity, you’d either have to manually collect and update information on all pools or use a centralized third-party solution.
That’s unless you know how to index. With indexing, you can easily store the smart contract data during its lifetime and save it alongside transaction IDs and block numbers, facilitating speedy retrieval.
Indexing from scratch involves:
- Writing high-performance code
- Setting up a database to store the data you retrieve in ordered form in (indexed)
- Create an API for access to that database
- Run an archive node and get all the transactions related to the information you’re looking for
- Keep processing any new transactions as they happen
- Rinse and repeat
An arduous task further exacerbated by the lack of standards for retrieving data in Web3. That’s where indexing protocols come in handy.
They bring order into the chaos, and relieve devs of the tasks of running their own archive nodes.
Indexing Protocols
The Graph was among the first to offer indexing for Web3 devs without requiring signing a service agreement with a centralized provider. Instead, using its blockchain data service dApps can tap into an open data marketplace powered by its native token GRT.
The graph’s network ties together a variety of network participants, including data consumers, indexers querying data on their behalf, and curators who pick the best subgraphs.
Subgraphs are one of the biggest innovations the team has introduced to Web3. In essence, a subgraph is a schema defining how data from a chain is retrieved, indexed, structured, and made queryable.
To ensure providers' honesty, the graph includes a dispute system where anyone doubting an indexer's work can challenge it and request proof of their work.
In January 2024, more than 1,700 subgraphs were generating queries on the Graph.
Why build an alternative?
Despite its success as a first-mover in the indexing space, things have changed. When the Graph launched, 90% of projects just needed access to EVM chains and ERC-20 transfers.
Nowadays, however, crypto devs aren’t limiting themselves to one chain, nor to onchain data.
The idea for Subsquid was born from the need for high-scale data retrieval while building a video platform. The existing alternative solutions simply didn’t support it or didn’t do so at an affordable price. After all, a small team cannot afford to hire 3 + service providers just to get data that’s technically publicly available.

Instead of putting all functionality in one layer, we took a modular approach, combining a decentralized data lake, where all onchain data is stored in raw format, with a decentralized query engine powered by Duck DB.
Subsquid is built for experienced devs who want to define their own schemas and manipulate the raw data for building at the edge.
It might be easy to dismiss indexing protocols as just another one of those infra projects, but ultimately, indexing is what facilitates devs to build user experiences that don’t suck.
And that is worth a lot.
For a more in-depth comparison between The Graph and Subsquid, check out our docs.